Dataset evaluation
This page describes the Dataset evaluation case: scoring dataset rows directly (no experiment outputs). Use it for manual scoring or LLM-as-judge on reference + model output columns.
Case summary
| Scope | Input | Use case |
|---|---|---|
| Dataset | A dataset with rows (no experiment outputs) | Score a dataset directly — e.g. manual scoring, or LLM-as-judge on reference + model output columns. |
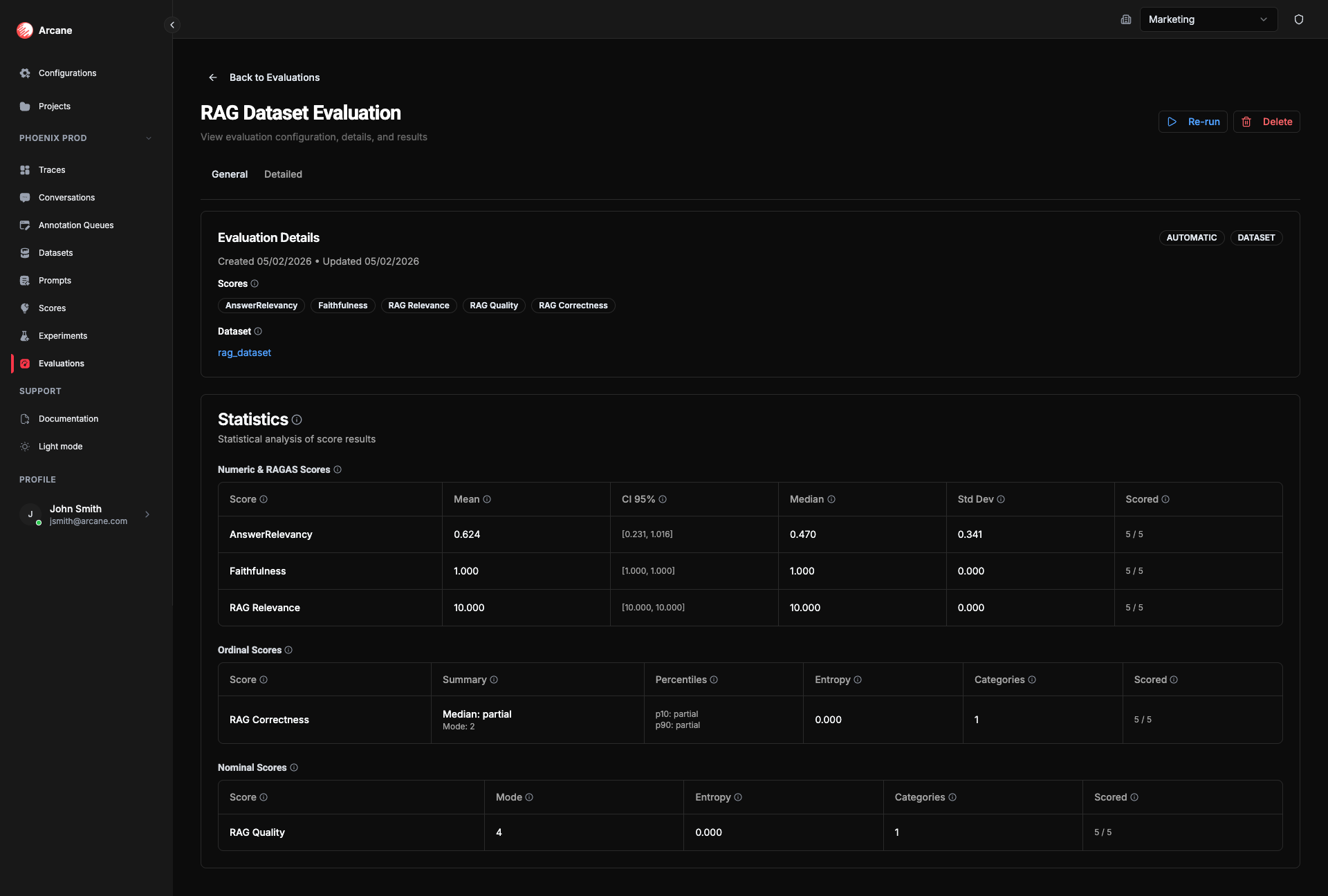
- General tab: Shows Dataset section and dataset-level statistics per score.
- Detailed tab: Dataset columns + score columns per row.
Creating a dataset evaluation
- Click New evaluation.
- Set Evaluation Scope to Dataset.
- Select the Dataset and one or more Scores.
- Click Create Evaluation. The evaluation runs automatically.
Scores run on each dataset row. For LLM-as-judge scores, the model evaluates inputs/outputs from dataset columns; for manual scores, enter results in the Detailed tab.
Statistics
Summary statistics are shown on the General tab. They are computed over all scored dataset rows. The exact metrics depend on the score type.
Why they matter: Statistics turn per-row scores into a single view of quality. They help you establish a baseline (e.g. mean or median), see how consistent or spread out results are (std dev, percentiles), and gauge uncertainty (confidence intervals). Use them to decide whether the dataset is ready to drive experiments, to spot gaps (e.g. many unscored rows), or to track quality over time as you add or change data.
Numeric & RAGAS scores
For continuous scores (e.g. 0–1, 0–10):
| Statistic | What it means | Why useful |
|---|---|---|
| Mean | Average value across all scored rows. See Mean. | Use as the primary summary for numeric scores—track quality at a glance. |
| CI 95% | 95% confidence interval for the mean; wider CI = more uncertainty. See Confidence interval. | Judge whether a score is reliably good or bad and whether you need more data. |
| Median | Middle value (50th percentile). See Median. | Less sensitive to outliers than the mean—use for a robust typical value. |
| Std Dev | Standard deviation—measures spread. See Standard deviation. | See how consistent results are; low std dev = stable quality. |
| Scored | Number of rows with a score vs total rows (e.g. 45/50). | Spot gaps (e.g. missing manual labels) and know coverage. |
Ordinal scores
For ordered categories (e.g. Poor → Fair → Good):
| Statistic | What it means | Why useful |
|---|---|---|
| Summary | Median (typical category) and Mode (most common category). See Median, Mode. | See both central tendency and what the model outputs most often. |
| Percentiles | p10 and p90—10th and 90th percentile categories. See Percentile. | Show the range of responses. |
| Entropy | Measures diversity of responses. See Entropy. | Higher entropy = more spread across categories. |
| Categories | Number of distinct ordinal levels (e.g. 5 for a 1–5 scale). | Know the scale size. |
| Scored | Number of rows with a score vs total rows. | Spot gaps and know coverage. |
Additional ordinal metrics:
- Pass rate — Proportion of results in acceptable categories (based on score's Acceptable Set). Why useful: See what share of results meet your quality bar.
- Tail mass below — Proportion of results below a threshold rank (based on score's Threshold Rank). Why useful: See how many outcomes fall in the worst categories.
Nominal scores
For unordered categories (e.g. labels):
| Statistic | What it means | Why useful |
|---|---|---|
| Mode | Most frequent category. See Mode. | Shows the dominant label in the distribution. |
| Entropy | Measures diversity of responses. See Entropy. | Higher entropy = more spread across categories. |
| Categories | Number of distinct categories (labels). | Know how many distinct labels appear. |
| Scored | Number of rows with a score vs total rows. | Spot gaps and know coverage. |
Detailed tab
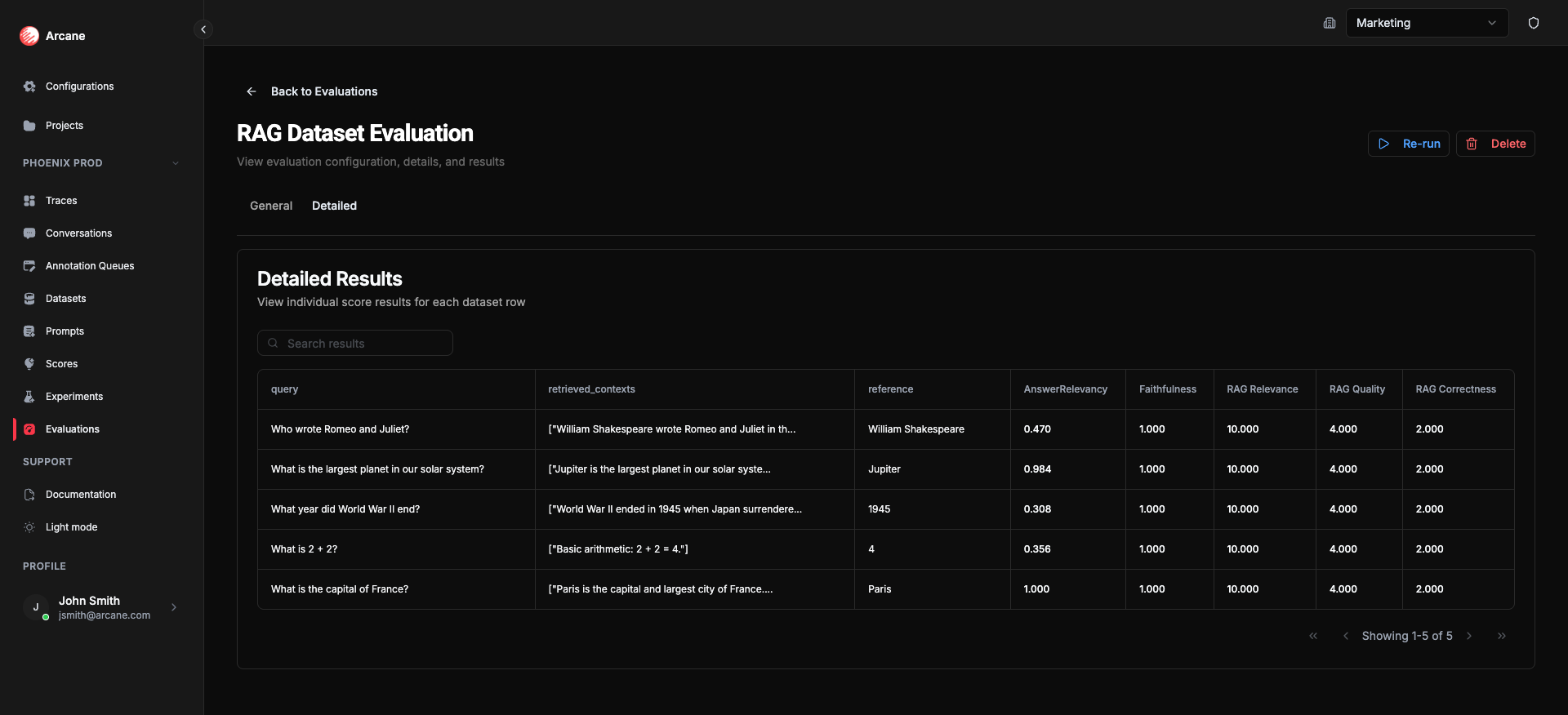
- Search results — filter rows.
- Table — dataset columns plus score columns (one per score).
- Copy to clipboard — copy cell values.
- Pagination — navigate through rows.
Each row shows dataset inputs and the score value for each metric.
Statistical references
For deeper understanding of the statistical concepts used in this evaluation case:
Descriptive statistics
- Mean — Wikipedia: Arithmetic mean
- Median — Wikipedia: Median
- Standard deviation — Wikipedia: Standard deviation
- Confidence interval — Wikipedia: Confidence interval
- Percentiles — Wikipedia: Percentile
- Mode — Wikipedia: Mode (statistics)
- Entropy — Wikipedia: Entropy (information theory)
Related
- Evaluations — overview and list.
- Single experiment evaluation — scoring one experiment's outputs.
- Multiple experiment evaluation — scoring and comparing 2+ experiments.